Chat Service Architecture: Persistence
Playing League of Legends for years now, I’ve formed a meaningful network of social connections with other gamers around the world. Whether they’re friends from work, former classmates, or players I’ve been matchmade with, they all have an important place on my friends list. The ability to easily play with these friends greatly enhances my experience with the game. It would be disastrous if something ever happened to that social graph—trying to remember and re-friend all of my 200+ friends would be as bad as losing my phone and all of its stored contacts.
I trust that Riot chat servers will persist information about my account—for example, the roster of my friends, metadata about a certain buddy, or the list of players that I have blocked. Furthermore, that data should be available to me at any time, anywhere, and stored securely so that only I can access it. In this article, I’ll walk through a brief history of our chat persistence layer and also outline the architecture that powers it today. I hope anyone facing a technical storage and persistence problem will find this post useful and interesting.
Early MySQL days
A few years ago, before the size of the LoL player base really started taking off, we made the decision to build chat servers using an open source XMPP server implementation: ejabberd. (You can read more about the protocol and server-side implementation in previous posts of mine.) In the past ejabberd offered only a few persistence layers: you could either use mnesia or an ODBC backend (which meant MSSQL, PostgreSQL, or MySQL servers).
We chose MySQL as the main store for chat data because scale wasn’t our primary concern at the time, and we had a lot of in-house experience with it. The implication was that all data that needed to be stored on the server and persisted between player logins had to be saved to MySQL. This included:
- Friends lists (aka rosters) and metadata about your friends such as notes, groups, friendship status, creation date, etc.
- Privacy lists: a register of blocked players whom you don’t want to hear from.
- Offline messages: all chat messages that were sent to you while you were offline, and which should be delivered as soon as you log back in.
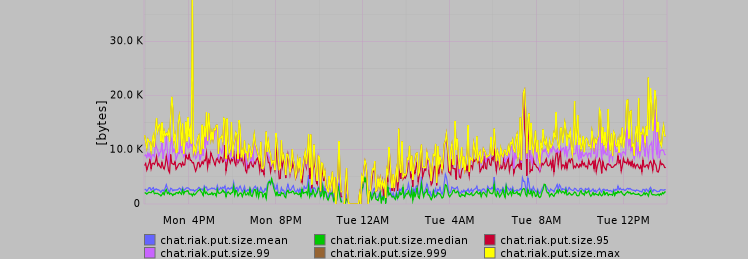
We built each shard to have three MySQL servers: one instance each for primary, backup, and ETL (Extract, Transform, Load). The primary is responsible for handling reads and writes from the chat servers and replicating its data to both the backup and ETL servers. The backup instance is there to (surprise!) snapshot data and be ready to act as the primary server in the case of either maintenance or failure of the original primary. Finally, the ETL server is used for data analysis and can be deployed on slightly less performant hardware.
Overall, chat shards using MySQL as a persistency backend look like this:
Player Base Growth
Over time, as the number of League of Legends players grew, we started encountering some trouble: the chat servers began overloading the MySQL primary instance. Players were seeing issues when loading their rosters, inviting new friends, or editing player notes. This sparked many internal discussions about the future of the MySQL backend, which led to identifying a few major pain points with the architecture as it stood:
- The MySQL primary needed to be scaled vertically—in order to achieve more capacity, we had to continually add more memory plus extremely expensive storage (e.g. FusionIO). This would have become a bottleneck to shipping value to players in the form of new features, and that’s something Riot takes extremely seriously.
- The primary also acted as a single point of failure in our system. Even small glitches in its performance resulted in timeouts when players would load their friends list. Despite having a backup server, transient problems that did not trigger failover were enough to impact the overall system. Major outages (caused by software or hardware) often snowballed into service downtime and significant manual work to resolve the issue.
- As the data set started to grow, schema migrations of any kind became extremely costly. Their application required careful planning, extreme diligence, and often hours of scheduled chat downtime. This significantly slowed development and delayed the release of features to players.
We evaluated several possible solutions to the problems listed above. Options included application-level sharding of MySQL, MySQL Cluster, Cassandra, and Riak. We encountered difficulties in quickly recovering from synchronous replication issues while evaluating both sharded and clustered MySQL. Cassandra was certainly a viable choice, but it imposed schema constraints that we really wanted to avoid. The last option - Riak - proved to be a flexible, scalable, and fault tolerant data store and we decided to proceed with it.
Riak
In the traditional world of relational database management systems (RDBMS), data is typically modelled as a set of tabular relations between entities stored in the system. In the vast majority of cases, users of RDBMS access and manage their data by means of SQL. NoSQL systems, such as Riak, depart from tabular relations. This introduces some complexity, but also a few noteworthy advantages. Typically NoSQL databases put engineers in a much more relaxed environment: schema-less interfaces allow for faster iteration; horizontal scalability removes the burden of many scale problems; and data is protected by internal replication. On a very high level, Riak is a distributed key-value NoSQL database that can be scaled horizontally in linear fashion and also provides AP (availability and partition tolerance) semantics as defined by the CAP theorem.
Migrations to Riak
Moving from MySQL to NoSQL meant major changes. We had a lot to learn about the CAP theorem, eventual consistency model, and a few other interesting concepts that Riak relies on.
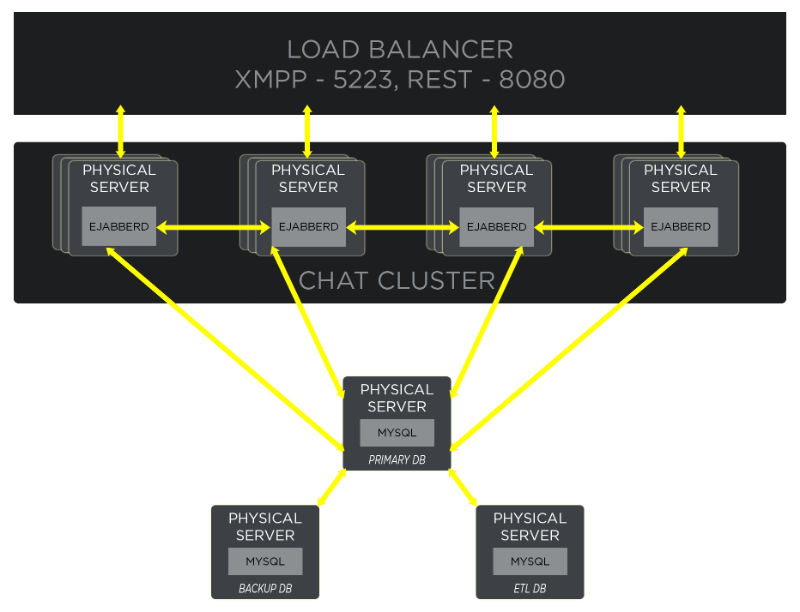
To quickly rollout Riak globally, we decided to reuse our existing chat hardware and co-locate the data stores on the same servers as chat. This allowed us to avoid the long process of acquiring and rebuilding servers around the world, as well as the costs of new machines. We ended up with the following architecture:
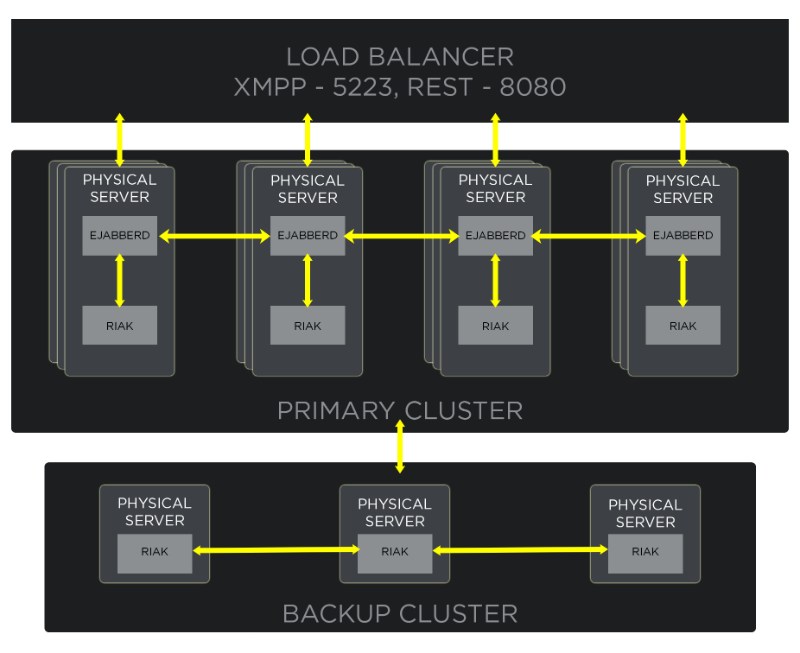
Deploying Riak instances to the same hardware as our chat services is a simple matter of deployment tool configuration (Chef, in our case) and has proven to be a very solid and predictable way of handling our clusters.
In this architecture each chat server connects to one of the available Riak instances via a protocol buffers interface, with a preference to choose an instance running locally on the same machine. In cases when the persistent protocol buffers connection is terminated, the chat service will automatically reconnect to another instance to ensure no player data is lost. Chat servers also monitor the Riak cluster topology—whenever it changes, they try to balance the connections across all cluster members (including the locally running Riak instance).
Internally, Riak uses a leveldb bucket backend with settings that allow for multiple versions of the same object (e.g. allow_mult = true, last_write_wins = false), and a replication factor set between 3 and 5 depending on the bucket type and importance. We consider friends lists highly important and therefore replicate them to more partitions. An example of less important data could be messages sent to a player while they were not logged in.
Write conflicts arise due to the distributed nature of the system, as well as from external events such as network partitions. Aphyr provides an excellent introduction to the write contention problem on his blog. In the traditional RDBMS world, the atomicity of transactions is ensured by implementing locking with a two-phase commit protocol. This approach sacrifices availability in order to guarantee that data is always strongly consistent on all servers running in the cluster. Unfortunately, this type of consistency does not work well in a distributed ecosystem, and therefore is relaxed in favor of eventual consistency properties. We approached this by implementing application level CRDTs (Convergent Replicated Data Types, scroll to the 'State-based CRDTs' section of the Wikipedia entry) that allow chat servers to resolve potential siblings lists in a predictable and automated fashion.
Let’s consider Bob and Charlie—players who would like to become friends with Alice. It just so happens that they send friend invites to Alice at the same time, which modifies Alice’s friends list concurrently from two different chat servers. Both updates to the Alice object succeed—however, Riak internally stores both versions of the updated friends lists (one with Bob's invite, the other with Charlie's). The next time Alice logs in and chat servers read her roster from Riak they will detect the conflict and merge the logs, ending up with both invites waiting for Alice's approval.
As a result, when a chat server wants to store an object it first encodes it into a CRDT structure, which is then JSON-encoded (so it’s easily readable by multiple services), and finally compressed. Here’s an example of the structured data we store in Riak (player friends list CRDT, JSON-encoded):
[mptaszek@na1chat001 ~]$ curl localhost:8097/buckets/NA1_roster/keys/sum1234 | gunzip | jq .
{
"v": 1,
"log": [
{
"val": {
"created_at": "2015-09-17 03:44:42",
"priority": 2,
"group": "**Default",
"askm": "",
"ask": "none",
"sub": "none",
"nick": "0xDEADB33F",
"jid": "[email protected]"
},
"type": "add",
"ts": 1442461482936116
},
{
"val": [
"sum98765",
"pvp.net",
"out"
],
"type": "change_ask",
"ts": 1442461483381002
},
{
"val": [
"sum112211",
"pvp.net",
""
],
"type": "del",
"ts": 1442461487937193
}
],
"val": [
{
"created_at": "2015-01-02 03:12:00",
"group": "**Default",
"askm": "",
"ask": "none",
"sub": "both",
"nick": "Teemo Ward",
"jid": "[email protected]"
},
{
"created_at": "2014-10-23 10:32:47",
"priority": "3",
"group": "**Default",
"askm": "",
"note": "Mom",
"ask": "none",
"sub": "both",
"nick": "Mooooorg",
"jid": "[email protected]"
},
...
],
"mod": "mod_roster_riak",
"ts": 1442461482739733
}
As you can see in the example payload, players’ rosters are simple lists of friends, with a mutation log attached to them. This mutation log consists of all state changes in form of log statements, e.g. changing friendship status, deleting items from the list, or adding new items to the list.
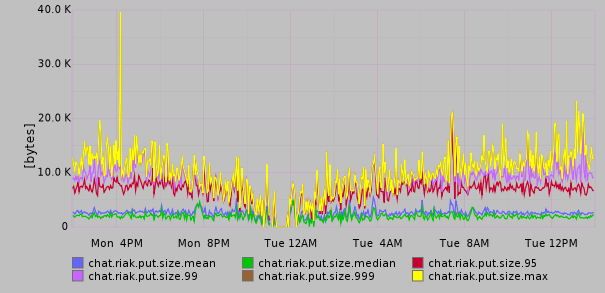
Although Riak offers on-disk snappy compression we found out the hard way that large objects (1MB+) really upset it, and sibling explosion can even cause service downtime. JSON compresses extremely nicely, and allows us to reduce the 95th percentile of object sizes stored in Riak from ~100kB to ~10kB. The graph below shows the distribution of object sizes we put in Riak throughout a day in the EU West (EUW) region:
Thanks to extensive LevelDB caching and the fact that the entire social graph almost fits into memory, 99.9% of our Riak queries finish within ~8ms (we almost never hit the disk):
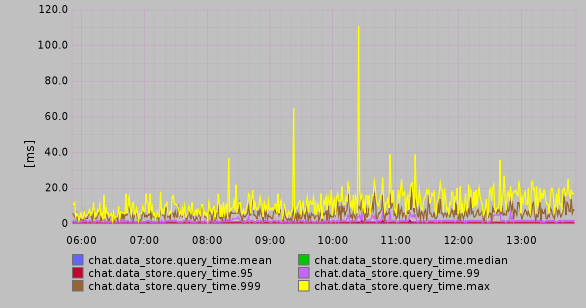
The loading of friends lists (including uncompressing, parsing JSON, merging CRDTs, and constructing the list in memory) takes less than 10ms in 99% of cases:
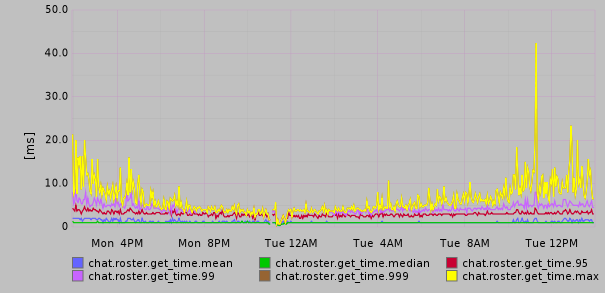
Additionally, we’ve set up a Riak backup cluster that we keep in sync with the production live cluster via Multi Data Center Replication. This is to protect players from data loss due to a massive failure in the data center, or bugs that might accidentally issue the NoSQL equivalent of a DELETE FROM users;. We periodically snapshot LevelDB data on the backup cluster so that it can be restored at any time without significant effort.
Production shard snapshots are also extremely useful when load testing chat servers: they allow us to mimic 1:1 social relations between players in different regions and see how small changes (for instance, bumping maximum length of the friends lists from 300 to 325) might affect the system.
Summary
Migrating chat servers from MySQL gave us unbelievable freedom in developing new features and allowed the service to operate in a stable way even in the case of partial cluster failures. Sure, Riak required a significant paradigm shift in how we think of data stores but in the end it was worth it! After months of migrating over a dozen shards around the world we have half of League’s players migrated to chat on Riak, with the remainder coming early in 2016.
The migrations unblocked feature development, allowing us to implement features such as push notification support for the upcoming mobile client and increased friends list size when we launched the Facebook Friend Importer last year. On top of that, handling players’ queries has never been faster—overall we’ve noticed significant improvement in query execution times. For example, the number of slow queries (ie. those taking more than a second to complete) dropped from tens of thousands per server to less than a 50 per day in the EUN shard. This translates directly into faster login times for players and zero failures (caused by query timeouts) when attempting to add a new friend. Finally, thanks to Riak’s reliability we have not lost a single minute of service uptime even when faced with disk failures or network failures!
Data storage is an extremely broad topic, and I am aware that I only discussed the tip of the iceberg here. If you have any comments or questions about details please don’t hesitate to post them in the comments below. Thanks!
For more information, check out the rest of this series:
Part I: Protocol
Part II: Servers
Part III: Persistence (this article)