
Cleaning Up Data Debt in League
Hey there. I’m Stephen “Riot FloofyRice” Zhang and I’m a technical developer in QA on the Content Efficiency team, which focuses on building internal tools. I want to talk about our efforts to clean up one of our bigger problems at Riot: data debt. Data debt occurs when content is developed on top of a system that has tech debt. As a result, changing an old system is often risky, and teams are incentivized to create new content in a “better” form in order to mitigate breaking existing functionality with a refactor. As priorities and deadlines change, tech debt cleanup often slides in priority, leading to a proliferation of standards. Bill Clark’s "A Taxonomy of Tech Debt" is a fantastic primer on the subject if you want to learn more.
For this project, the data debt that had accumulated over the years was blocking new features that would accelerate the creative process for artists, designers, and other content creators working on League. We decided the time investment was worth it and set out to find a solution. What we landed on was a process called “assetization.” In this article, I'll talk about this process, including some of the speed bumps along the way - and I'll show you how something like this can happen:

Two textures: same name, one with correct alpha, one without. Importer found the wrong one.
Why assetization?
Our previous asset management solution had a few major flaws: non-explicit references, hidden information, and inconsistent standards. I'll go into each of these in depth below.
Non-explicit references
In the previous system, all references to assets would refer to a file only by name, rather than containing a full, explicit path. This led to all sorts of confusion around where references originated and what happened if two files in different folders had the same filename (which was more abundant than we hoped). Over time, the widespread lack of knowability ate away at the productivity of our content creators as they struggled to solve complicated bugs while working. A lot of champions are created by utilizing existing spells and champions as templates, so the lack of knowability spread quickly to newer champions, causing pain as teams tried to iterate.
Hidden information
Another major issue with our old file management system for visual effects was the amount of special casing that had accumulated over the years. One such case was how we loaded skins and skin effects. If the assets followed a specific naming convention, the file management would replace references to the base skin version of the file with a skin specific reference (e.g. the Ezreal_Skin02_Q VFX would replace Ezreal_Base_Q VFX when playing as Skin2). In addition, there were a couple of asset extensions that would be replaced by the game engine. However, this did not change the VFX files referencing those assets, leading to properties that worked but referred to nonexistent assets. While this replacement works, it generated confusion when names were slightly off or when we needed to know certain details like whether a texture was skin-specific.

Inconsistent standards
As the amount of content in League has grown, various art and tools teams have attempted to establish better standards to ensure sustainability. However, due to a lack of information and/or time, these cleanup attempts were often stopped short. Teams would agree to develop future content in a new format and create a ticket to clean up the previous data, but without a holistic effort, those tickets were easily lost to the backlog. As a result, there were 4 or 5 different ways to organize your VFX, leading to confusion and wasted time.
League’s data problems had grown to the point where the paper cuts from interacting with the system were actively hampering the creativity of our designers and artists. More and more time was spent trying to fight with the system rather than exploring ideas.
So what’s the new solution?
With these problems in mind, we knew we needed a new system. We proposed a system that used two main components: WAD files and the Game Data Server. WAD files are a neatly compressed and bundled set of data that includes everything required to load a specific piece of content. The Game Data Server is a way to manage loose property values in game and provide authoring tools for content creators to add new content. Some other benefits include:
- Explicit, enforced long path file references - prevents ambiguity about which file is being referenced and requires the file’s existence
- Smaller patch sizes, smaller install sizes, and less surface area for leaked content since we package only the assets referenced by game data as opposed to entire folders
- Access to newer tech such as materials and shaders that were built without short path support
- Faster build and iteration times
- Hot reload of textures and property values so our content creators can iterate with real-time feedback
To support our existing content, we “assetized” each champion, which can be boiled down to 5 broad steps:
- Renaming and re-organizing all VFX data to match the latest standards set by the art discipline
- Conversion of all VFX data to a format similar to what the game receives
- Bundling VFX together in WAD files so that the game knows which VFX files to use without needing them to be in specific locations during development
- Updating all scripts and champion data to point to new asset locations
- Cleaning up all unused stale files that have piled up over the years
Our attack plan
The team committed to releasing every new champion and VGU following Kayn with the new data format. This was relatively straightforward for new champions, but our data debt reared its ugly head every time a team went to work on an existing champion. Sometimes art teams chose to create a new skin in the new data format without updating any of the previous skins. Cleanup tasks were put on the backlog and then slowly pushed to the bottom as they got deprioritized, resulting in many older champions with different data formats for each skin. We decided that the continuous paper cuts of the various formats had slowed down our content creators enough and it was time to fix the old champions as well. Without ties to any particular skin, champion or deliverable, we had no product concerns pushing us to quickly solve the problem, and we were given the chance to clean up this data debt once and for all.
We began converting 2-4 champions every patch, which would have taken 30-50 patches. At that rate, we’d have to dedicate an engineer solely to this effort for the next couple years. What’s more, our bug rate was unacceptable, even at this relatively low velocity. Players were also seeing the pattern, allowing them to predict what surprises we had in store next. We knew we could do better in terms of both efficiency and quality, and we identified some workflow and tooling changes that would help get us to the finish line. After scoping out some initial risks, we decided on an aggressive timeline and prepared players: we’d finish almost all the work between 8.6 and 8.8. 3 patches, 107 champions, 1240 skins, 120k files.

We focused our engineering efforts into 4 major areas:
- Building a safe workspace
- Improving existing tools
- Building new tools
- Establishing an initial test strategy
Building a safe workspace
The first thing our team discussed was how to reduce our impact on the ongoing changes other teams were making to the game. Working within the main development branch tied us to League’s 2 week release cadence, which led to a couple risks we wanted to avoid:
- Work in progress would be unacceptable as unfinished changes would completely break a champion
- Broken builds on the main branch would block us from working
We landed on creating a separate branch in source control with its own deployed test environment. While there were some cons to this approach, it yielded plenty of pros.
- Testing was closely aligned with live, reducing the amount of redundant testing after integration back to the main branch
- Flexibility in terms of which champions to pull into each sprint based on blocking issues
- We could iterate on multiple champions at once for extended periods of time without impacting internal playtests
- We needed to keep our work branch and the main branch in sync; source control integration from one branch to another is very time consuming and brittle
- We could potentially stomp balance or gameplay changes happening on live without vigilant communication
Improving existing tools
Next step was to improve our existing tools. Our VFX importer, which brings old VFX data into the new system, was incomplete and error prone. We applied a profiling macro system we have in place for League to the importer tool and tested an import of a simple champion to find areas of code we could speed up.
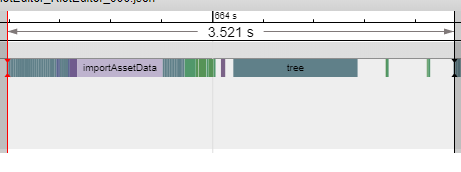
Time breakdown of a single asset in a VFX import
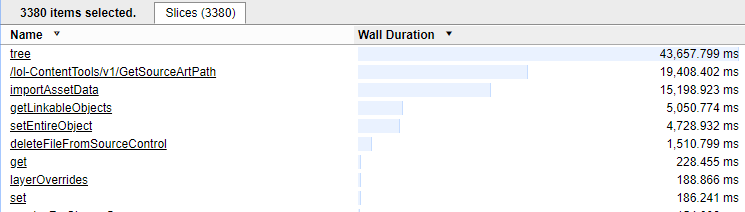
Small snippet of time spent
Looking at the trace, the time it took to import the actual asset (importAssetData) is about the same as the tree section. The tree section is the time spent refreshing the file explorer built into the editor housing the importer. Given that the user is not interacting with the tool at all during this process, why is it updating the file explorer?
It turns out this quirk was due to the way our editor hooks into Qt’s event system. Qt is a GUI framework that we use for the Game Data Server and its accompanying editor. When creating events in Qt5, the events are put into a queue that gets dispatched whenever the main event loop runs. The editor normally refreshes and reloads its various widgets whenever underlying data is changed. Since the import process is a batch operation that modifies hundreds of files, we expected the main event loop to wait until all operations were done.
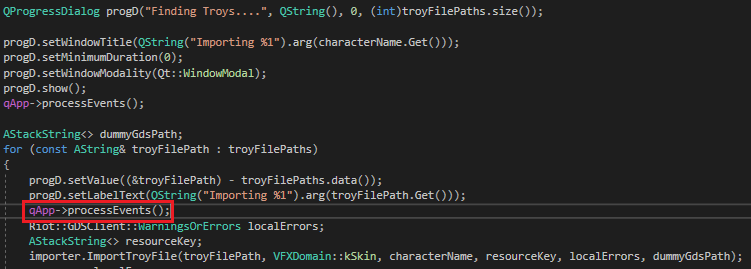
We had originally been calling qApp->processEvents() when one developer wanted to know how much longer the importer would take. We solved this by adding a progress bar and by manually processing the event queue whenever one VFX file was finished. This worked for updating, but as the logic grew, the progress bar ended up more expensive than the import process itself.
Every field in the VFX file that was not a default value would queue one event to reload the editor’s UI. When we processed the queue to tick the progress bar, the UI would reload many times over. This made an average champion with ~200 VFX files take 20-30 minutes to import into the VFX editor, with some more complex champions reaching upwards of an hour. This was ironic considering the progress bar was added to help us time the thing in the first place. Once we removed it, we saw massive performance improvements, with average champion import times going from 20-30 minutes to 3-5 minutes.
Building new tools
Up until now, the Content Efficiency team had partnered with VFX artists on various development teams to assetize the champions they wanted to work on next. They were the subject matter experts and could help us pinpoint what exactly we needed to change. But VFX artists spent roughly a week of time to clean up an older champion, which would be too slow given our desired velocity.
Instead, we put together a Python command line tool that would file crawl through a champion’s data and return an HTML report of all improperly named files, all referenced files, and the files referencing them. It also cleaned unused VFX files as well as unused variables and properties. It also compressed textures and resized textures that were bigger than 2048x2048 to a reasonable size. This eliminated the need for an artist to do rote work and freed them up to work on what they do best: making awesome content.
In anticipation for the merge back from our work branch into the main branch, we wrote a Python script to help generate the branch mappings given a list of champions that we wanted to integrate. This allowed us to safely pick which champions to ship in the upcoming patch and avoid in-progress work.
Establishing an initial test strategy
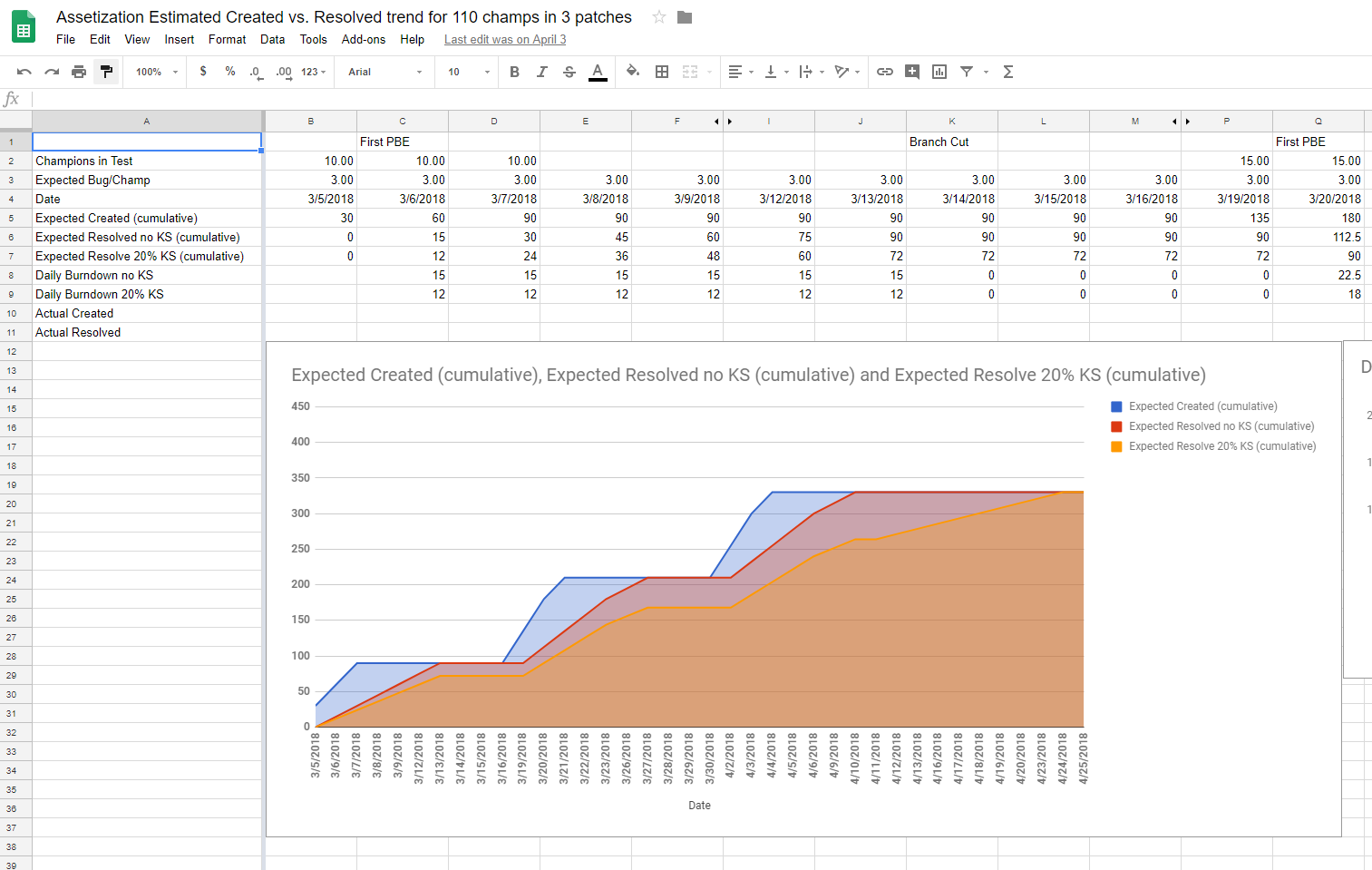
Looking at the champions we’d assetized before the project, we averaged around 3 major bugs per champion. This was a good starting point for estimating the total amount of time we would lose to bug triage and resolution. Given the QA resources we could pull together for this project, we estimated that we could test 10 champions in a day. We graphed an estimate of the bugs we would generate per day and what the bug burndown would look like if we aimed to fix all bugs per patch or let 20% of non-gameplay impacting bugs through per patch.
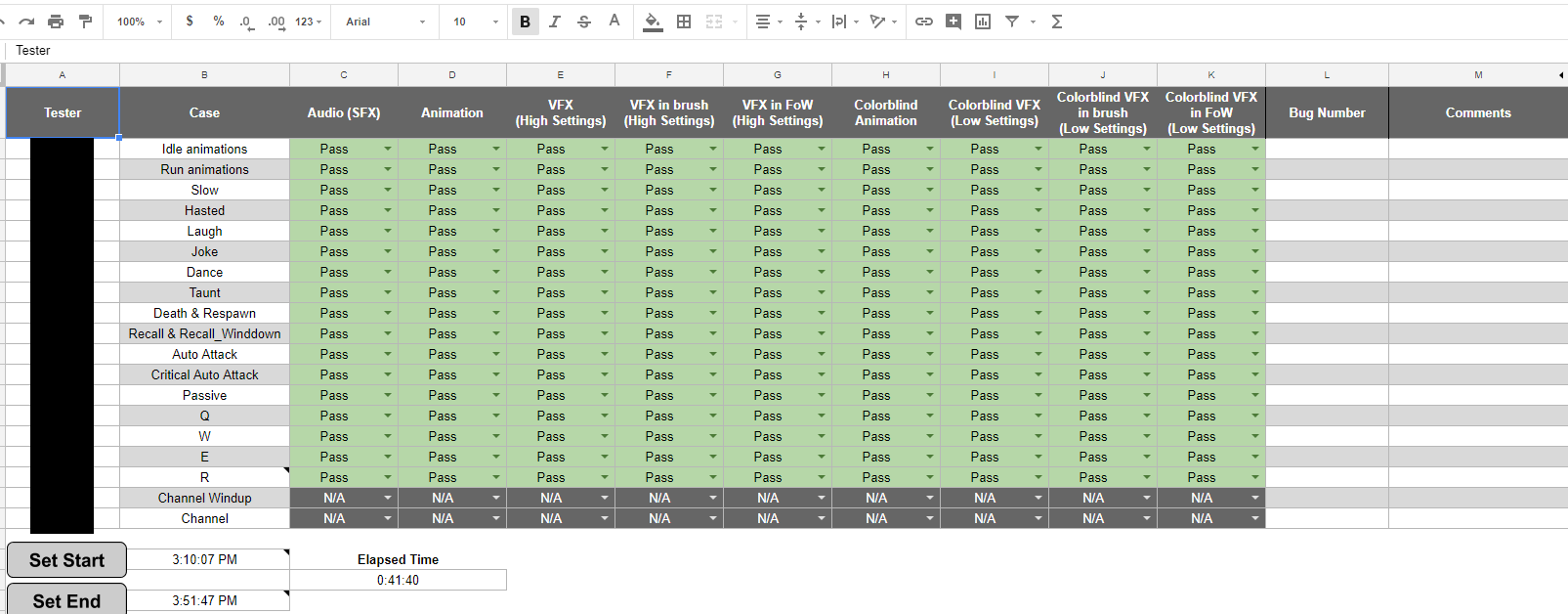
We also coordinated with our existing skins QA team to provide best practices for how to test VFX without being experts. We opted to not test functionality to limit the scope of work since the process only targeted visual data.
Dry run - patch 8.3
With an initial set of processes in place, the team needed to rigorously test the pipeline we’d built; rather than winging it live in 8.6 and failing due to unforeseen issues, we found a patch that was purposefully light and decided to test our plan with a smaller subset of champions.

In order to iron out as many issues as we could, we decided on 14 champions that ranged in difficulty from easy to “Lulu,” whose age, ownership-transferring pet, and model complexity (Lulu, polymorph, and Pix, each with different assets and standards of organization) warranted a separate category. The estimations were heavily based on assumptions around the age of the champion since last rework, complexity of the champion’s kit, the number of skins with unique particles, etc.
With this, everything was in place to jump into the project. We started working as soon as 8.3 started internal development.
How did we do?
Going into the initial dry run, we expected to hit some road bumps while gaining insight into the predictability of the work ahead. We had planned for a retrospective shortly after 8.3’s release to discuss how to mitigate the challenges we faced.
Work was unsustainable
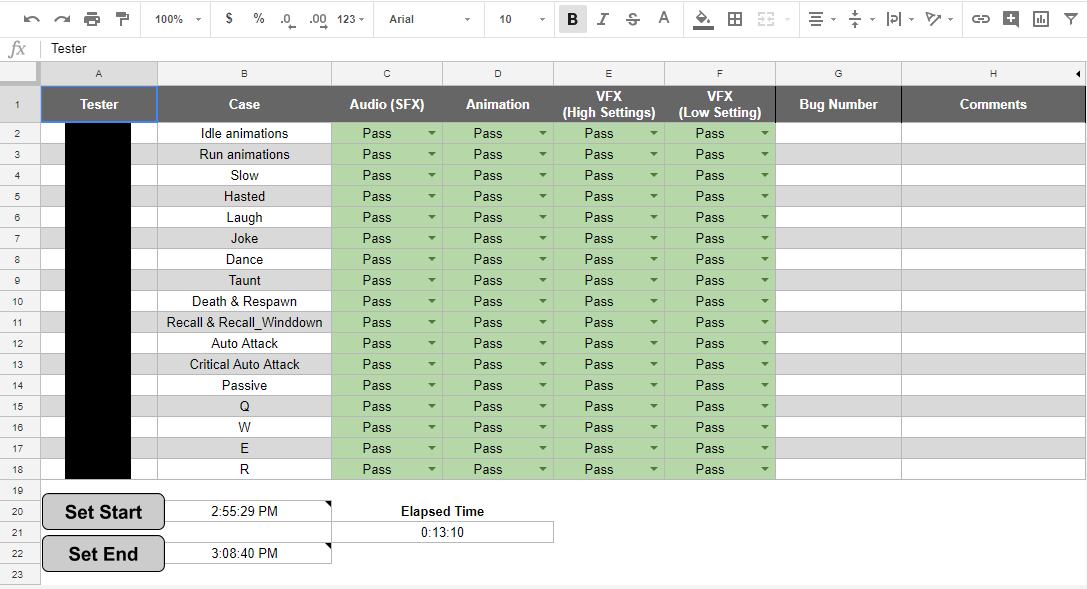
We quickly discovered that testing VFX for colorblind, fog of war, and bloodless mode was overkill. None of the VFX for our 14 test champions failed those tests. Instead, the engineers wrote a couple scripts to find all special cases for each system and specifically marked those abilities for additional testing. We tested Singed, Ashe, and Darius for colorblind, fog of war, and bloodless mode respectively as champions who utilized those systems heavily. After working with QA, we removed roughly 120 test cases per skin per champion, dropping the average testing time to 15 minutes.
The engineers ended up working significant overtime to hit the 14 champion goal for the dry run. That was no good, but we wanted to thoroughly stress test our system without cutting corners to mitigate the risk of a defect impacting LoL in the wild. How could we balance the team’s throughput without sacrificing quality? We knew that slimming down the workload would increase risk, so rather than trying to find ways to reduce the amount of work, we optimized around reducing stress and interruptions while doing work in the office. We had the other members of Content Efficiency take over live supporting the artists so we didn’t have to do bug fixes and triage on top of the work. The team also tried to keep the area quiet so that we could focus and collaborate without headphones.
After struggling with just 14 champions, we knew that 33 within the timespan of a patch would be nearly impossible at our current pace. To combat this, engineers started to convert champions that came out cleanly with the current tools, and built a queue of champions for QA to test while we improved tools and unlocked the ability to cleanly assetize champs who had caused issues before.
Incorrect asset resolutions
We saw a large number of bugs generated when two files with the same name were located in different directories. Depending on the paths, the importer could pick the wrong one; the resulting bugs were particularly difficult to fix because the errors would manifest differently depending on where the asset was being used.

A placeholder Thresh character texture used instead of Aatrox’s character texture because they were named the same but in slightly different folder structures

Camille is gone! Her Q-empowered textures were named the same as her character texture in a different folder.

The alpha on some textures were incorrect, resulting in really odd black and white noise
Since these bugs manifested in many different ways, we approached solutions from multiple directions. First, we increased visibility whenever things went wrong. We wrapped every failure point with some additional logging so we knew exactly which file failed at which step. We also added additional logging to the VFX importer so that anytime two files with the same name in different locations were found, it would get logged to a file.
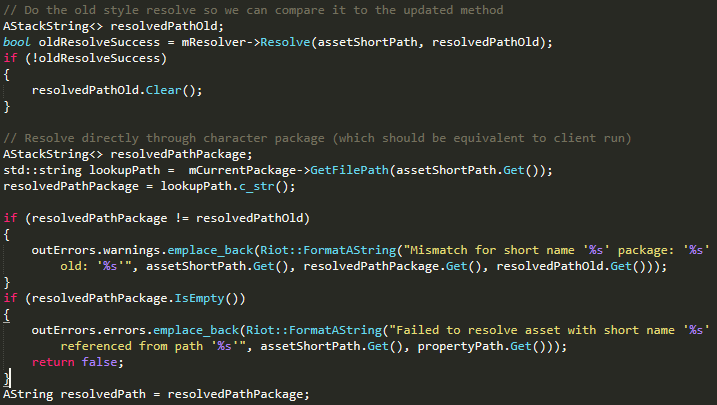
The second piece of the solution was porting League’s package manager into the importer. The package manager is responsible for converting all short file references into explicit full paths, and differed from our existing implementation. Rather than rewrite the whole system from scratch, we used some finesse and delicately grafted the League package manager onto the importer. We left the previous implementation in place so we could detect when things were different than expected.
The real deal: 8.6 to 8.8
In the downtime between our test run and 8.5, we worked on improving our tools, removing bugs, and improving efficiency. We also started to convert champions in the work branch ahead of time to build up a buffer so we could always have champions in testing. This gave us more time to work on champions with weirder data formats as well as make any systematic changes to the tooling to improve future assetizations.
With the changes we made from 8.3, we were able to import 35 champions by 8.6 and get everything tested with a small buffer of time to spare. While we uncovered a couple more bugs in the importer, we opted to continue manually fixing the edge cases instead of improving the tool because we deemed the fixes riskier than running a find and replace.
Cutting out the rote details of the actual assetizations themselves, we continued to iterate every patch and were able to complete the assetization process in patch 8.8.
Bugs created versus resolved
How did we do?
The project was a success! Players noticed little to no changes related to the champions, and the art and champion teams can now iterate with all the benefits of the new asset management system mentioned above. One fun fact: we ended up with more bugs fixed than bugs generated, as we fixed many legacy bugs that were once difficult to fix but trivial with proper data dependency tracking.
One example was a bug on placeholder textures displaying on Black Belt Udyr. While fixing this bug, we realized the issue was occuring in the spell script for Udyr and that it was because Spirit Guard Udyr’s specific VFX were always playing, but the system wouldn’t find it on any skin that wasn’t Spirit Guard. By fixing this, we also fixed a different issue with Spirit Guard Udyr, where the VFX played on his hands didn’t update based on what level his stances were at. This had broken in the past and was never prioritized because it was difficult to figure out how it broke.

This placeholder was Black Belt Udyr attempting to play Spirit Guard Udyr’s VFX and not finding it
Conclusion
While we put a lot of time and effort into trying to make sure our plan was well-researched and well-thought-out, we would never have reached our final result without the 8.3 dry run. That crucial test of our processes vetted our assumptions, which led to many important discoveries around the deficiencies of our tooling. It also gave us a better understanding of the breadth of data debt we could run into.
The biggest lesson was the importance of jumping in and testing, instead of just relying on planning. All our planning helped by setting a good benchmark for success, but this project wouldn’t have been successful without us trying it on a small subset of champions to test our theories. Testing allowed us to avoid many potential issues that could’ve snagged us in the larger push, and gave us a better idea of the actual scope of work required.
As a result of our work, the average time required to integrate a new skin into the next patch has dropped dramatically as the process has become significantly easier. Artists are able to leverage all the features in the Riot Editor’s VFX tool Particle Town, including access to shaders and materials. All new skins for champions are now accessible in Particle Town, which has made creating new content easier and more enjoyable. Moving forward, we want to continue to make the process of creating content as streamlined as possible. Our next steps include revisiting our tooling to more effectively capture edge cases, such as champion icons which are referenced by both spell scripts and character data.
Thank you for reading! Feel free to leave any comments or questions below.