
Docker & Jenkins: Data that Persists
In this tutorial, you’ll learn:
- How to persist Docker data with volumes
- How to make and use Docker volumes
- How to share data in volumes with other containers
- How to preserve Jenkins job and plugin data
In the last blog post we discussed taking more control of our Jenkins Docker image by wrapping the Cloudbees image with our own Dockerfile. This empowered us to set some basic defaults that we previously passed in every time we ran docker run. We also took the opportunity to define where to place Jenkins logs and how to use docker exec to poke around our running container.
We made some great progress, but we still needed some kind of data persistence to really make this useful. Containers and their data are ephemeral, so we’re still losing all of our Jenkins plugin and job data every time we restart the container. The Cloudbees documentation even tells us that we’re going to need to use volumes to preserve data. They recommend a quick way to store data on your Docker Host, outside of your running containers, by mounting a local host folder. This is a traditional method of persisting information that requires your Dockerhost to be a mount point.
There is another way, however, and that’s to use a Docker data volume to persist your storage. You can read up about Data Volumes in Docker’s documentation here.
HOST MOUNTED VOLUMES VS DATA VOLUMES
Host Mounted Volumes
When I refer to a “Host Mounted Volume” I am referencing the idea that your Docker host machine stores the data in its file system and mounts that physical storage into the container when you use docker run to start the container.
This approach has many advantages, the most obvious one being its ease of use. In more complex environments, your data could actually be network or serially attached storage, giving you a lot of space and performance.
This approach also has a drawback: it requires that you pre-configure the mount point on your Dockerhost. This eliminates two of Docker’s bigger advantages, namely container portability and applications that can run anywhere. If you want a truly portable Docker container that can run on any host, you can’t rely on any expectations of how that host is configured when you make your docker run call.
Data Volumes
This is where Docker data volumes can help. Volumes are actually really slick tech based on something Docker already does. Whenever you make a container, Docker has to persist the data in that container somewhere. Loosely speaking, that data is stored in Dockers filesystem. Each container you make gets its own volume. These days Docker will let you make your own volumes in addition to the default volume a container will use. This is handy because the volumes you make won’t be removed when the container is removed.
Using Docker volumes allows Docker containers to share data without the requirement that the host be configured with a proper mount point. Users can interact with the containers via Docker commands and never need to touch the host.
There are drawbacks to data volumes as well. Performance is a tad slower as you’re maintaining data through Docker’s virtualized file system, so it may not be ideal for applications that need the very best in I/O performance. For most apps, however, this won’t be noticeable. Complexity is also increased as you now have to make sure the volumes are created and you will need to remove them when you want to reset them.
To be clear, either approach is 100% valid and really depends on how exactly you want to work. My own opinion is that applications should be as independent as possible. For the purposes of this article I’ll be showing you how to use data volumes.
GETTING STARTED
We’ll start with the Dockerfile we ended up with from the last blog post. For reference here it is:
FROM jenkins/jenkins:2.112
LABEL maintainer=”[email protected]”
USER root
RUN mkdir /var/log/jenkins
RUN chown -R jenkins:jenkins /var/log/jenkins
USER jenkins
ENV JAVA_OPTS="-Xmx8192m"
ENV JENKINS_OPTS="--handlerCountMax=300 --logfile=/var/log/jenkins/jenkins.log"PREPARING THE DATA VOLUME
Volumes are super easy to create. We have two things we want to potentially persist regardless of whether our Jenkins application starts or stops. Log files (which we put in /var/log/jenkins previously) and the Jenkins application data itself (that’s where it keeps jobs, plugin installations, configurations etc). For storage, I like to keep logs separate from application data. I’ve found it’s easiest to do this with two dedicated Docker volumes.
Let’s go ahead and create the new data volume:
docker volume create jenkins-dataYou’ll note that you get a simple output message with the name of the volume you made. To confirm you made that volume, you can get a list of all volumes you’ve made:
docker volume lsYou should see “jenkins-data” in the list. You may see many other entries as well; those are probably dynamically created volumes tied to any containers you have on your system.
If you need to delete this volume for some reason (say you want to nuke your logs from orbit) you can do so easily:
docker volume rm jenkins-dataAs a super pro tip, if you find your docker subsystem eating a lot of disk space, it might be because you have a lot of “zombie” volumes lying around. These are data volumes that no longer have owners (containers), you can prune them with:
docker volume pruneBe careful, however. This will remove any volume that no longer has a parent container. If you were persisting data in a volume and at the time you run this command its container isn’t in the list of containers on the host (it has been removed) you’ll lose your data.
Now that we get the basics of volumes, let’s go ahead and create the log volume as well:
docker volume create jenkins-log
USING THE DATA AND LOG VOLUMES
This part is easy. We’re going to specify the volumes as mount points and targets in our docker run command. We’ll take each volume we made and plant it in the directory location where we want it to exist inside our container. For our log location, let’s use /var/log/jenkins.
To make use of it we just need to add the --mount directive to our docker run call like so:
docker run -p 8080:8080 -p 50000:50000 --name=jenkins-master --mount
source=jenkins-log,target=/var/log/jenkins -d myjenkinsYou can see above that I've added a new port mapping for port 50000. This is to handle connections from JNLP based build slaves. I'll talk about this more in a future blog post but wanted to include it here in case you start using this as the basis for your own Jenkins server.
Note that Docker is smart enough to apply the read/write permissions of the target directories that we assigned in our Dockerfile when it mounts in the volume. You can verify everything still works by tailing the log file again:
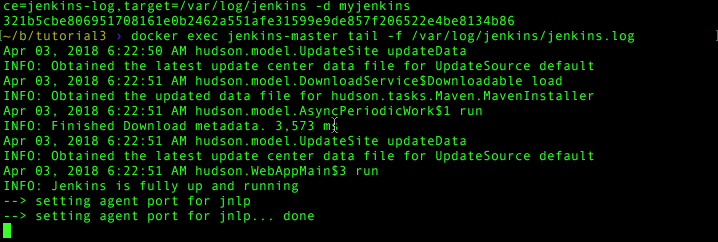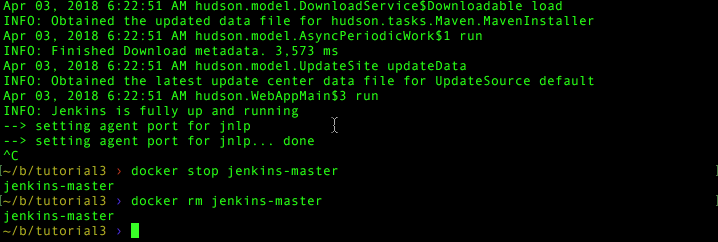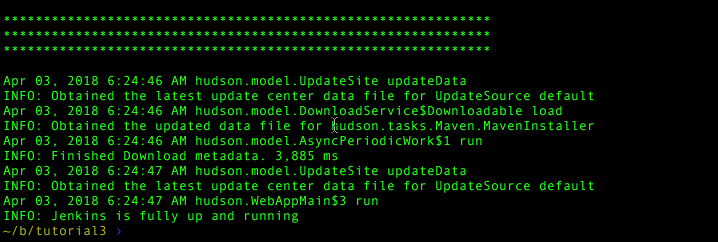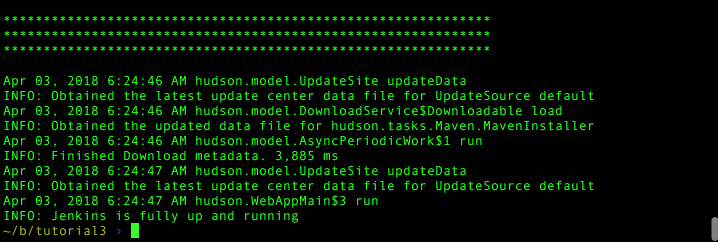
docker exec jenkins-master tail -f /var/log/jenkins/jenkins.log
But how do we know the volume mount works? Easy: by default Jenkins appends to its log file. A simple start/clean/restart can prove it. Ctrl-c to exit your run then:
docker stop jenkins-master
docker rm jenkins-master
docker run -p 8080:8080 -p 50000:50000 --name=jenkins-master --mount
source=jenkins-log,target=/var/log/jenkins -d myjenkins
docker exec jenkins-master cat /var/log/jenkins/jenkins.logYou should see the first, then second Jenkins startup messages in the log. Jenkins can now crash, or be upgraded, and we’ll always have the old log. Of course this means you have to cleanup that log and log directory as you see fit just like you would on a regular Jenkins host.
Don’t forget about docker cp. If you have data in a volume that you want to copy out but you’ve lost the container that mounts it, you can use any container to mount the volume and copy the data out. Let’s try this with our Jenkins log now sitting in a Docker volume:
docker run -d --name mylogcopy --mount source=jenkins-log,target=/var/log/jenkins debian:stretch
docker cp mylogcopy:/var/log/jenkins/jenkins.log jenkins.logPreserving log data is just a minor advantage - we really did this to save key Jenkins data like plugins and jobs between container restarts. Using the log file was a simple way to demonstrate how things work.
SAVING JENKINS HOME DIR
Before we save our Jenkins data there’s one annoyance with the default Cloudbee’s Docker image. It stores the uncompressed Jenkins war file in jenkins_home, which means we’d preserve this data between Jenkins runs. This is not ideal as we don’t need to save this data and it could cause confusion when moving between Jenkins versions. So let’s use another Jenkins startup option to move it to /var/cache/jenkins.
Edit the jenkins-master Dockerfile and update the JENKINS_OPTS line to:
ENV JENKINS_OPTS="--handlerCountMax=300 --logfile=/var/log/jenkins/jenkins.log --webroot=/var/cache/jenkins/war"This sets the Jenkins webroot. However, we now need to make sure this directory exists and is permissioned to the Jenkins user, so update the section where we create the log directory to look like this:
USER root
RUN mkdir /var/log/jenkins
RUN mkdir /var/cache/jenkins
RUN chown -R jenkins:jenkins /var/log/jenkins
RUN chown -R jenkins:jenkins /var/cache/jenkins
USER jenkinsSave your Dockerfile, rebuild your jenkins-master image, and restart it. Please note that there’s an additional mount command to leverage the new jenkins-data volume below.
docker stop jenkins-master
docker rm jenkins-master
docker build -t myjenkins .
docker run -p 8080:8080 -p 50000:50000 --name=jenkins-master --mount
source=jenkins-log,target=/var/log/jenkins --mount
source=jenkins-data,target=/var/jenkins_home -d myjenkinsYour container should start. You can confirm we moved the WAR file correctly by running the following command:
docker exec jenkins-master ls /var/cache/jenkins/warYou should see the uncompressed contents there. But how do we know this fancy new layout saves Jenkins data?

TESTING PERSISTENT JOBS AND CONFIG BETWEEN RUNS
We can perform this test easily. With your jenkins-master container running, let’s go prep Jenkins and make a new build job!
- Point your browser to: http://localhost:8080
- You should see the Jenkins “first time install” setup screen
- Enter the admin password that was generated for you in the Jenkins log
a. Don’t remember how to get that? Use Docker! - Choose “install suggested plugins” for now
- Wait for all the plugins to install, then create an admin user (you can continue using the password you have if you want or make a new user)
- Once at the Jenkins landing page create a new job by clicking New Item
- Enter testjob for the item name
- Choose Freestyle software project
- Click ok
- Click save

Our new “useless for anything but testing” job should show up on the master job list. Now stop and remove your Jenkins container:
-
docker stop jenkins-master
-
docker rm jenkins-master
When jenkins-master is removed here, the jenkins-log and jenkins-data volumes still reference the virtual file system. If we wanted the data to go away we’d have to forcefully remove the volumes with the docker volume rm command.
In the old image we had, this would’ve also deleted our job and our Jenkins setup and plugin installs. When we recreate the container however:
1.
docker run -p 8080:8080 -p 50000:50000 --name=jenkins-master --mount
source=jenkins-log,target=/var/log/jenkins --mount
source=jenkins-data,target=/var/jenkins_home -d myjenkins2. Refresh your browser at http://localhost:8080/ and wait for Jenkins to start
We will have to log in again but that already means we’ve preserved the plugin installs and setup configuration. Once we log in we should find that our test job is still there. Mission accomplished!
CONCLUSION
As with the previous blog posts, you can find updates and example files from this post on my Github repository. You’ll note that the makefile has once again been updated and includes a new clean-data command if you want to wipe out your data container. It also has a new create-data command, which is called when we do make run to guarantee the volumes are created. Don’t worry, if volumes already exist they won’t be overwritten!
At this point we have a fully functioning Jenkins image. We can save our logs, jobs, and plugins because we placed jenkins_home in a data volume so it persists between container runs. As a side bonus, it will even persist data if the Docker daemon crashes, or the host restarts, because Docker preserves volumes until they are forcibly removed.
While we could start using this set up, in practice there are still some things that could stand to be improved. Here’s the short list:
- We’d like to proxy a web server like NGINX in front of our Jenkins container
- Managing multiple images and containers is starting to get annoying, even with a makefile. Is there an easier way?
- We need a way to back up our Jenkins environment, especially jobs
- What if we don’t want to use Debian as our base OS? What if we don’t like relying on external images?
- We haven’t done anything about build slaves. While this setup will allow any standard slave to connect, wouldn’t it be awesome if we could set up build slaves as Docker containers?
Each one of these is basically its own blog post. Up next we’re going to get a web proxy set up and discuss how we deal with having two containers: that means introducing Docker Compose. The other subjects such as build environments in containers, changing our base OS, and backing up Jenkins will be further out. Stay tuned!
For more information, check out the rest of this series:
Part I: Thinking Inside the Container
Part II: Putting Jenkins in a Docker Container
Part III: Docker & Jenkins: Data That Persists (this article)
Part IV: Jenkins, Docker, Proxies, and Compose
Part V: Taking Control of Your Docker Image
Part VI: Building with Jenkins Inside an Ephemeral Docker Container
Part VII: Tutorial: Building with Jenkins Inside an Ephemeral Docker Container
Part VIII: DockerCon Talk and the Story So Far