
Compressing Skeletal Animation Data
League of Legends has more than 125 champions, each with their own set of unique animations. (One of my faves? Sion’s dance, shown below—just one of his 38 animations.) These movements help to bring the champions to life: from determined movement to powerful spell casting to tragic deaths. (I see that last one too often.) As we’ve continued to introduce and rework champions, the total amount of animation data has become a larger burden on resources like run-time memory, patch sizes, and storage space.

In addition to animation data, the visuals included in the recent update to Summoner’s Rift place further demands on memory. The update uses a unique-texel approach, which enables more engaging visuals compared to the tiling approach originally used—however, it considerably increases the size of map textures in memory.
We put importance on continuing to support the broadest possible range of player hardware so that everyone can enjoy that awesome Undead Juggernaut boogie. With the increased memory requirements of new animations and the map update, we looked for ways to reduce memory usage. One avenue we investigated was compressing in-game skeletal animation data to shrink the memory footprint while minimizing quality loss and any adverse impact to performance.
We could’ve approached compressing animation data in many ways. With this post, I'll introduce the two main techniques we pursued: quantization and curve fitting. Compression always leads to a trade-off between quality lost and memory gained, so I’ll discuss what we found acceptable. I’ll also go over how we organized the data to maximize performance. I’ll use concepts like quaternions and spline curves, so if you’re unfamiliar with them, I’ve included a list of useful resources at the end of this post.
I want to note that nothing I’m mentioning in the techniques here is completely new. They are a practical application of knowledge shared by fellow game developers. I’ll also add that game engine developer BitSquid’s blog is especially helpful and worth mentioning.
Quantization
Quantization is the process of constraining values from a continuous set of possibilities to a relatively small discrete set. Skeletal animations have position, rotation, and scale data. We can easily quantize 3-dimensional vectors, which are used to represent position and scale, by getting their min/max range and uniformly partitioning across that range. But the lion's share of skeletal animation data usually comes from rotations.
We use quaternions to represent rotations in 3D space. Our approach to quantizing rotation data exploits particular mathematical properties of quaternions. We assume unit quaternions, where all components are in the range [-1,1], and begin by identifying the x, y, z, or w component having the largest absolute value. Then, we discard that component and save the other three, since we can easily calculate the omitted component using the fact that unit quaternions satisfy x² + y² + z² + w² = 1. By omitting the largest component, we can limit the range of the remaining three components to [-1/sqrt(2), 1/sqrt(2)]—remember, in a unit quaternion a component outside of this range must have the largest absolute value and therefore be the component we’d omit. We are maximizing the precision by quantizing into a smaller range than [-1, 1], which is the range we would’ve used if we hadn’t excluded the largest component. This also allows us to avoid reconstructing a component with a small value, which is prone to an increased error.

Using this approach, we allocate 15 bits for each of the three saved components and 2 bits to specify the omitted component. Each quaternion therefore occupies a total of 48 bits (with 1 bit unused) as illustrated by the picture above. By comparison, a raw quaternion uses a 32-bit floating-point number for each of the components, resulting in a total usage of 128 bits. With a reduction from 128 bits to 48 bits, we achieve a compression ratio of 0.375.
This 48-bit quantization of quaternions guarantees a numerical precision of 0.000043. You can feel (if you have an instinct for floating-point numbers) that this should suffice for most cases. In fact, when we applied this quantization to all animations, no animator could detect any quality loss from the conversion. Additionally, we can apply these conversions at load time rather than going through a batch conversion process and patching them later, as the quantization is such a light-weight process computationally.
Curve Fitting
For further compression, we looked into applying curve fitting to the changing values of the quaternions. This is the process of constructing a curve, or mathematical function, with the best fit to a series of data points. We specifically used Catmull-Rom splines, which can be represented as a 3rd-order polynomial. You need four control points to define a section of Catmull-Rom spline as the following diagram from Wikipedia shows:
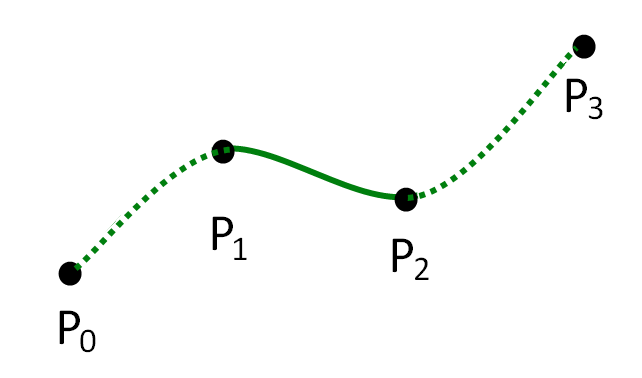
Source: Wikipedia
{kind=link}
To perform the actual fitting, we use an iterative approach to reducing error. The process begins with only two keyframes that comprise the start and end of the animation in question. We add more keyframes iteratively in order to reduce the curve’s overall error to an acceptable level. In each iteration, we identify the section between keyframes with the largest error and insert a new keyframe at its midpoint. This process of inserting a keyframe into a section with the largest error is repeated until the error for every section falls below a given threshold.
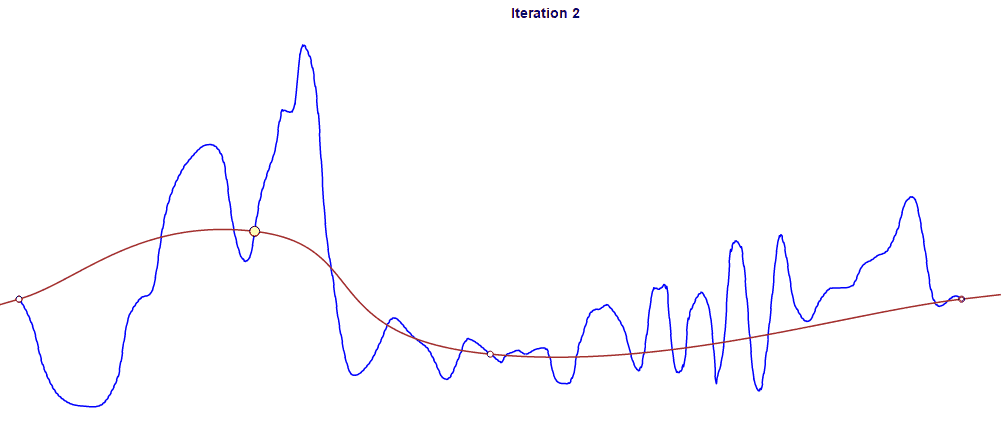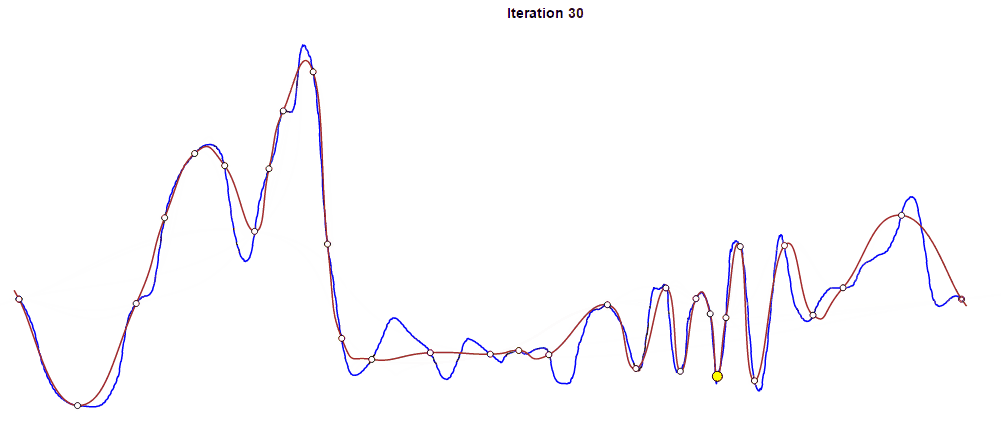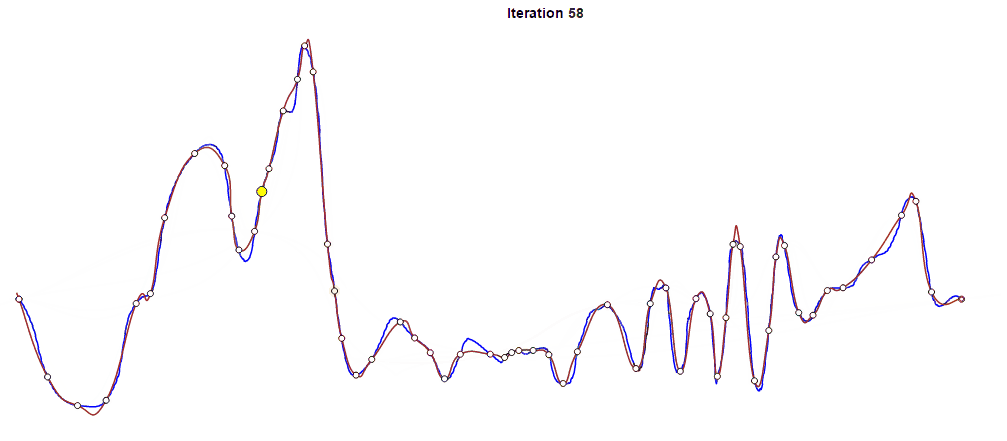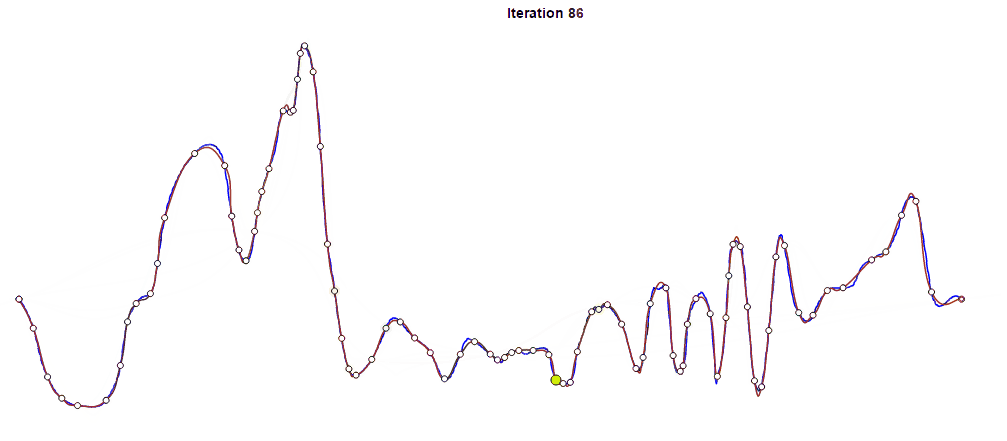
You can see above how the fitting curve in red approaches the original curve in blue as the iteration proceeds. Yellow dots represent additional new frames at each iteration. In this case, we compressed the 661 original frames to 90 frames after 88 iterations.
Don’t forget to align the four control-point quaternions before doing the curve interpolation. A quaternion Q and its negation -Q represent the same rotation, but without alignment the resulting rotations might not represent an interpolation along the shortest path. For example, consider a ship heading north that is preparing to turn east. Without proper quaternion alignment, this ship could turn through 270 degrees counter-clockwise, instead of 90 degrees clockwise.
Curve fitting enabled further compression from quantized results with a rate ranging from 25% to 70%. We found setting proper error thresholds for position/rotation/scale data crucial to achieving a high compression rate without a significant loss in visual experience.
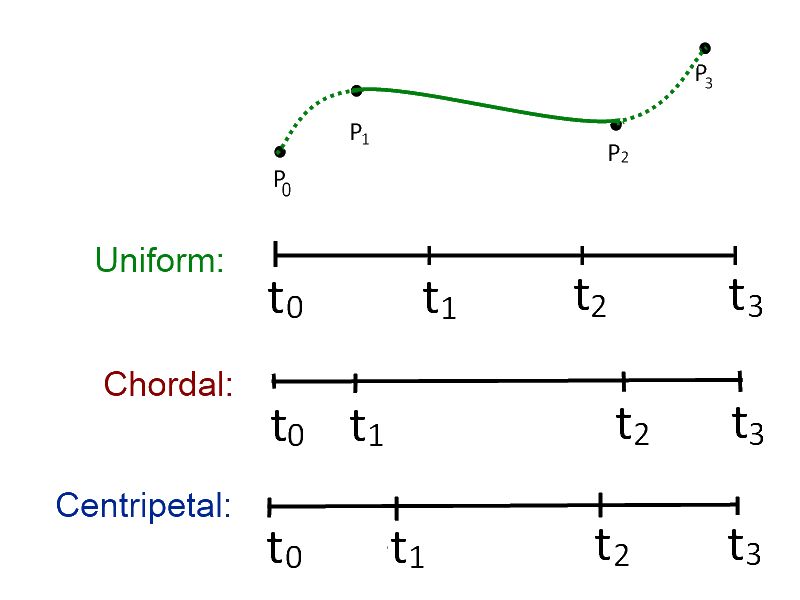
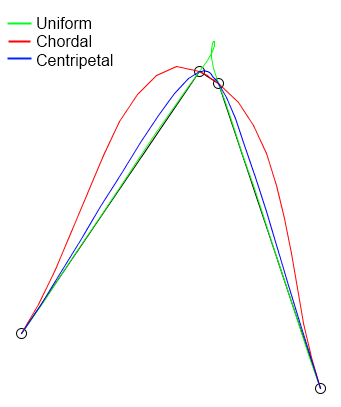
 We also considered knot parameterization of the spline curve for better compression. In the case of animation data, a parameterization based on given keyframe timings is the most natural. Still, as you can see below (from Wikipedia, again), the shape of a curve with the same four control points depends on which knot parameterization—uniform, chordal, or centripetal—we use.
We also considered knot parameterization of the spline curve for better compression. In the case of animation data, a parameterization based on given keyframe timings is the most natural. Still, as you can see below (from Wikipedia, again), the shape of a curve with the same four control points depends on which knot parameterization—uniform, chordal, or centripetal—we use.
Source: Wikipedia
{kind=link}
Source: Wikipedia
{kind=link}
These techniques brought about noticeable quality loss for some animations. We could mitigate most of this loss by using tighter error thresholds, but obviously the compression rate would suffer. Therefore, our animators reviewed each case to properly balance between quality and compression ratio. Also, unlike the quantization case, a load-time conversion was not an option since the curve-fitting process is computationally heavy—we had to preprocess all of the existing animation data.
Loss Mitigation
The most noticeable artifact that arose from the compression was foot sliding, which really reared its ugly head in animations where the character's foot or any end-effector should be stationary throughout.

You can easily see in the video above how the foot that should be stationary keeps swimming. This is due to the hierarchical nature of bones in a skeletal rigging, where error accumulates as the animation affects segments farther from the root joint. One way we mitigate this issue is using a technique we call “adaptive error margins.” It means you tighten the error threshold if the joint has a longer chain of descendants, instead of applying the same threshold to every joint. For instance, an end effector uses given margins as they are, but its parent halves them, its grandparent divides them by three, and so on. This tightening of error margins on parent joints limits the amount of error that cascades down to descendants.
Game Programming Gems 7 introduces another approach called “reducing cumulative errors in skeletal animation.” We internally call this “joint pinning.” For a pinned joint (like the foot), we do not use the source data stream for the joint as provided, but calculate new local transformation data that will offset the errors introduced in compressing its ancestors. The book contains even more great material on this topic.
Cache-Friendly Data Organization
Finally, let’s discuss ways we efficiently implemented the concepts discussed so far. As we developed these techniques, we remained mindful of the wide range of player hardware and were very careful not to introduce any performance regressions. One thing my team focused on was achieving cache-friendly data organization.
A crucial step we took was putting all keyframes (position/rotation/scale frames for every joint) into a single contiguous memory block. One common practice is creating a separate memory block for each channel per joint, but such seemingly natural organization can trigger several cache misses when evaluating a full skeletal pose at a given timing. We could put data into one block because the payload happens to be 48 bits for all channel types. As we saw earlier, we quantize quaternions to 48 bits, and we also quantize 3D vectors for position/scale to the same number of bits by assigning 16 bits to each of the x, y, and z components. You can check out the actual code struct used to represent a single compressed frame below:
struct CompressedFrame
{
// Normalized key time (0(0.0) - 65535(1.0))
uint16_t keyTime = 0;
uint16_t jointIndex = 0;
// Payload, which can be a quantized 3d vector or a quantized quaternion
// depending on what type of channel this data belongs to
uint16_t v[3];
ChannelType GetChannelType() const
{
// Most significant two bits of this 16bit index contains channel type info.
return static_cast<ChannelType>((jointIndex & (0xc000)) >> 14);
}
void SetChannelType(ChannelType type)
{
jointIndex |= (static_cast<uint16_t>(type) << 14);
}
std::uint16_t GetJointIndex() const
{
return jointIndex & 0x3fff;m
}
};
Here, we also quantized the key time to 16 bits. The jointIndex member variable specifies which joint this frame data belongs to. The v array contains the quantized payload. Distinguishing whether the payload is for position, rotation, or scale is important, and we use the two most significant bits of jointIndex to accomplish this. Using these bits in this manner limits jointIndex to 14 bits, or 16384 total joints—certainly sufficient for League of Legends champions that usually require less than 100 joints.
Properly ordering keyframes becomes critical with each of them, regardless of joint or channel type, in a single bucket. We could trivially order them by the key time (i.e. the keyTime member above), but problems quickly arise. Let's imagine what happens at run-time as an animation plays, with help from the pictures below:
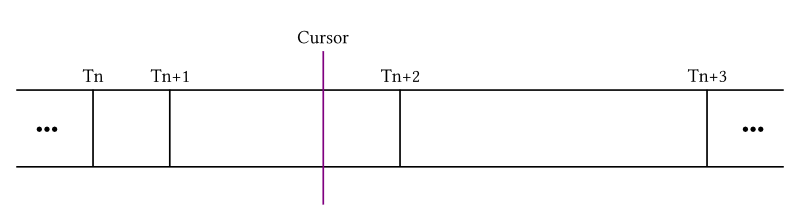
You can see four keyframes (sorted by key time) and a time cursor that designates the current timing of playback.You need info about Tn, Tn+1, Tn+2, and Tn+3 because evaluating a spline requires four control points. Given that the cursor's current position is past Tn and Tn+1, the cursor should already know about them. What about Tn+2 and Tn+3, which lie in the future from the cursor's perspective? You might think you can quickly linear-scan them since they are the two frames immediately following.
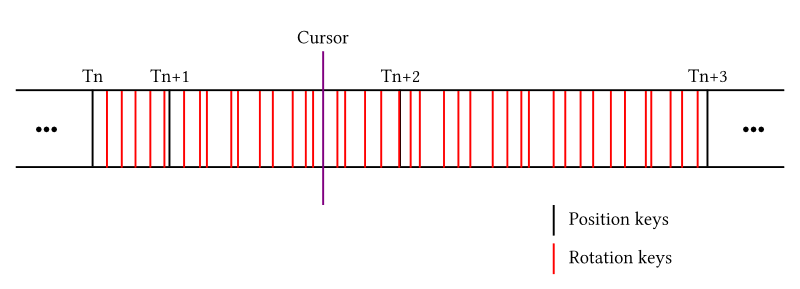
However, this approach isn’t optimal. Let's say those Ts are position frames. A lot of rotation frames may exist between two adjacent position frames (as you can see in the example above) if the animation happens to mostly consist of rotational changes. This results from our placement of all frames into a single bucket, so the linear-scan to find Tn+2 and Tn+3 is likely to be inefficient.
The trick to making the playback happen in a single pass linear-scan (and achieving the greatest benefit from the cache) is ordering frames by the time the key is needed instead of the key time. We need Tn+2 info once the cursor passes Tn's key time; therefore, we should order Tn+2 based on Tn's key time. Ordered this way, at any moment the cursor secures all the information needed for the current evaluation, so cache misses can be minimized. A diagram below illustrates how this ordering works in the case of an animation consisting of four position keys and nine rotation keys:

Hopefully this insight into our implementation of compression is helpful to anyone approaching a similar problem.
Conclusion
On average, the quantization technique I discussed in this article halved the memory requirements of League of Legends champions. We’re still in the process of applying the curve-fitting technique, since it requires a pre-processing of all data, but early results indicate that it will achieve a further 50% compression, meaning we’re down to 25% of the original requirement. I’m excited by this result and the opportunities for improved gameplay on all types of player hardware.
We can further explore many directions like 32-bit (instead of 48-bit) quaternion quantization, different knot parameterizations for curve fitting, least square fitting instead of the iterative approach, more tuning of how the iterative approach chooses a new key to add, and so on. Compression is a broad and deep topic, and we’ve only dipped our toe in its deep water with this article. Still, I hope you found this useful for tackling animation compressions. I’ve linked some relevant articles in the reference section below. Best of luck!
References
- Animation compression
- The BitSquid low level animation system
- Bitsquid Dev Blog – Low Level Animation — Part 2
- Digital Rune Blog – Character Animation Compression
- Unreal Engine 3 Animation Compression
- Reducing Cumulative Errors in Skeletal Animation, Bill Budge (Game Programming Gems 7)
- Curve fitting
- Compression in general
- Tools used to prepare materials for this article